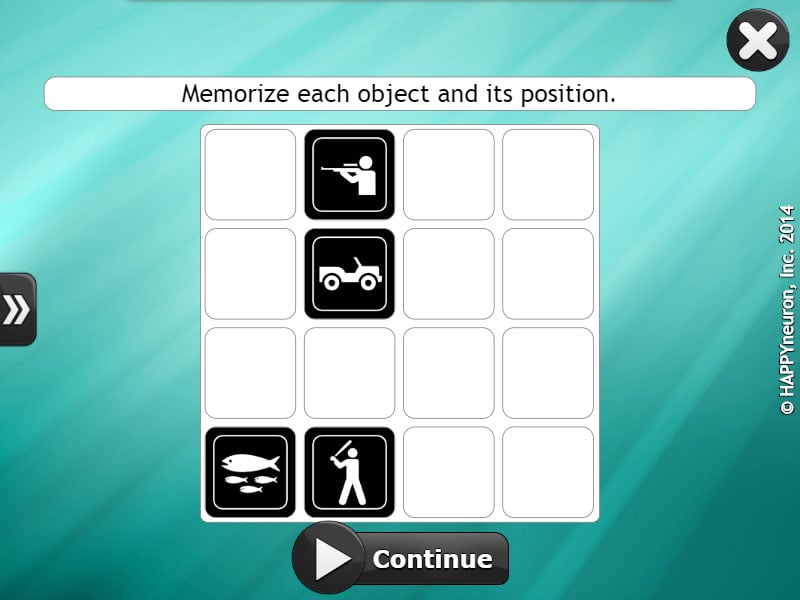
The right tempo-parietal cortex is at play in this exercise. This exercise is about creating associations between two types of information: an image and its location. Establishing the link with a strategy makes memorization easier. Attention to detail, good visual-spatial orientation, and visual memory are required. The user will engage their hippocampus while activating the connections between the visual processing streams to correctly identify, remember, and place the objects they have seen.